KI Text to Speech (Rede aus Text erzeugen)
HINWEIS Diese Funktion erfordert ein Abonnement für VEGAS Pro 365, VEGAS Pro Edit oder VEGAS Pro Post 365. Um diese Funktion zu nutzen, müssen Sie sich zunächst bei Ihrem VEGAS Hub-Konto anmelden (weitere Informationen finden Sie im Abschnitt VEGAS Hub).
Die Text-to-Speech-Funktion in VEGAS Pro ermöglicht es Ihnen, Text in Videos in Sprache umzuwandeln und als Audiodatei hinzuzufügen. Sie bietet eine effiziente Möglichkeit, große Textmengen in Sprache umzuwandeln, ohne professionelle Sprecher engagieren zu müssen. Mit dieser Funktion können Sie die KI-Technologie nutzen, um computergenerierte Stimmen in verschiedenen Sprachen und Sprachoptionen zu erzeugen. Darüber hinaus bietet es die Möglichkeit, Ihre Beiträge mit natürlich klingenden muttersprachlichen Stimmen in verschiedene Sprachen zu übersetzen. Darüber hinaus können Sie dank der Cloud-basierten Funktionalität nahtlos auf neue Stimmen und Funktionen zugreifen, ohne dass eine neue Software erstellt werden muss.
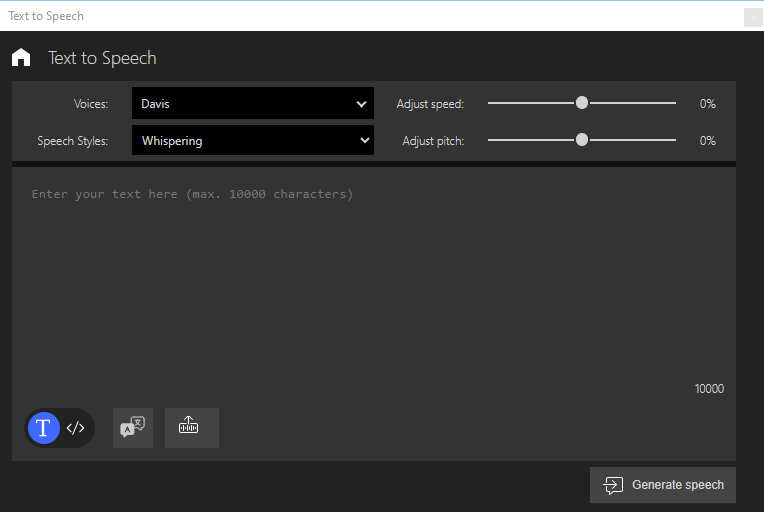
Umwandlung von Text in Sprache
-
Wählen Sie Extras | KI Text to Speech.
-
Geben Sie im Dialogfeld Text in Sprache den Text, den Sie in Audio umwandeln möchten, in das Textfeld ein.
-
Stil anpassen
Stimme ändern Klicken Sie auf die Dropdown-Liste Voices und wählen Sie die gewünschte Stimme aus. Geschwindigkeit anpassen Mit dem Schieberegler können Sie die Sprechgeschwindigkeit verringern oder erhöhen. Redestil ändern Für ausgewählte Stimmen können Sie zwischen verschiedenen Sprachstilen wählen. Tonhöhe einstellen
Mit dem Schieberegler können Sie die Tonhöhe verringern oder erhöhen. -
Klicken Sie auf GENERATE SPEECH. Der Text wird konvertiert und wiedergegeben.
Nun können Sie die erzeugte Sprache als Audiodatei speichern und in Ihr Projekt importieren.

Speichern der Audiodatei im Projekt
-
Klicken Sie auf Zu Projektmedien hinzufügen. Die erzeugte Audiodatei wird als .wav-Datei in Ihrem Projekt gespeichert.
Sie können auf den Ordner über das Fenster Project Mediazugreifen.
Audiodatei in das Projekt einfügen
-
Klicken Sie auf Insert on Timeline. Die Audiodatei wird als neues Audio-Event auf einer neuen Audiospur mit der Bezeichnung Synthesized Audio an der aktuellen Cursorposition in Ihrer Timeline eingefügt und automatisch im Projekt gespeichert.
Text übersetzen
-
Geben Sie den Text in das Textfeld ein.
-
Klicken Sie auf die Schaltfläche
 (Text übersetzen).
(Text übersetzen). -
Wählen Sie in dem angezeigten Dialogfeld die Sprachen aus:
-
Sprache des Textes: Sprache des eingegebenen Textes
-
Übersetzen in: Zielsprache
-
-
Klicken Sie auf die Schaltfläche Übersetzen. Der Text im Textfeld wird durch eine Übersetzung in der angegebenen Sprache ersetzt.
Laden von Text aus Titles & Text-Ereignissen in Text to Speech
Sie können den Text aus einem beliebigen Titel- und Textevent auf Ihrer Timeline in das Tool Text in Sprache laden, um eine Audiodatei für diesen Text zu erzeugen.
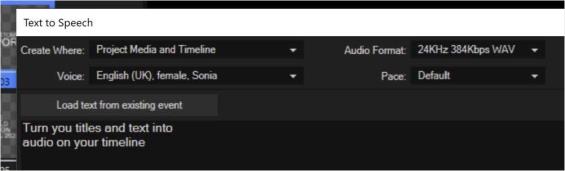
-
Klicken Sie auf das Ereignis, in dem sich die von Titles &Text erstellten Medien befinden, um es auszuwählen.
-
Klicken Sie im Dialogfeld "Text in Sprache" auf die Schaltfläche Text aus bestehendem Ereignis laden. Dadurch wird der Text aus dem Ereignis Titel & Text in das Texteingabefeld von Text to Speech geladen.
-
Zeigen Sie eine Vorschau des Tons an und nehmen Sie die gewünschten Änderungen vor.
SSML-Eingabemodus verwenden
SSML (Speech Synthesis Markup Language) ist eine Auszeichnungssprache, die speziell für die Steuerung der Ausgabe von Text-to-Speech-Systemen (TTS) entwickelt wurde. Es ermöglicht detaillierte Anweisungen zur Formatierung und Gestaltung der gesprochenen Sprache, z. B. zur Betonung bestimmter Wörter, zur Steuerung der Pausenlänge oder zur Änderung der Sprechgeschwindigkeit.
SSML bietet eine Reihe von Tags, die in den Text eingebettet werden können, um anzugeben, wie er ausgesprochen oder übermittelt werden soll. Diese Tags ermöglichen die Kontrolle über verschiedene Aspekte der Sprachsynthese, einschließlich Prosodie, Aussprache, Lautstärke und mehr.
 Weitere Informationen finden Sie unter https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-synthesis-markup
Weitere Informationen finden Sie unter https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-synthesis-markup
SSML-Beispiel
<speak version="1.0" xml:lang="string">
<voice name="en-US-ChristopherNeural" effect="eq_car" role="YoungAdultMale" >
Welcome <break strength="medium" /> to text to speech.
<p>
<prosody rate="slow">This is a sentence that will be spoken slowly.</prosody> <prosody rate="fast">This is a sentence that will be spoken quickly.</prosody>
</p>
<p>
<break time="1s"/>A pause of 1 second is inserted here.<break time="1s"/>
</p>
</voice>
<voice name="en-US-JennyMultilingualNeural" style="assistant">
<lang xml:lang="en-US">
Enjoy using the feature!
</lang>
<lang xml:lang="de-DE">
Viel Spaß beim Benutzen des Features!
</lang>
</voice>
</speak>